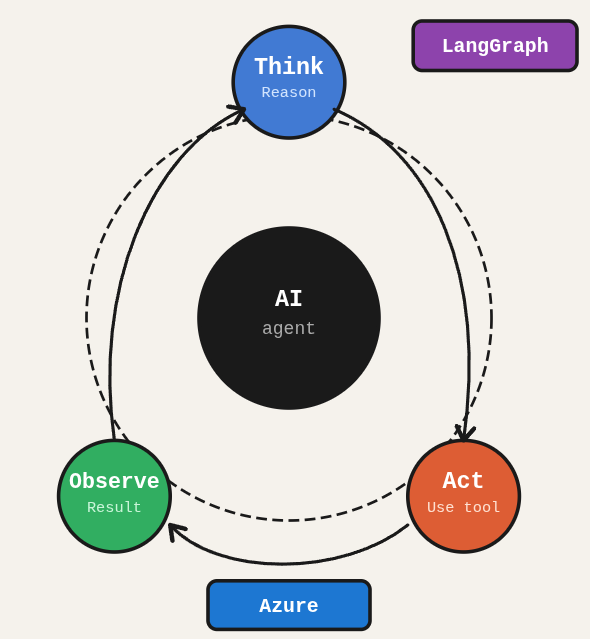
You want an AI agent that actually reasons, queries databases, and uses tools intelligently, not a chatbot that rephrases your question back with a different tone. The ReAct pattern with LangGraph and Azure OpenAI is how you build that.
TL;DR: Build a production-ready AI agent using LangGraph’s ReAct pattern with Elasticsearch (vector search), Neo4j (graph recommendations), and Streamlit (UI), deployed on Azure OpenAI.
Stack: Python, LangGraph, LangChain, Azure OpenAI, Elasticsearch, Neo4j, Streamlit, Poetry
Level: Advanced
Reading time: ~20 min
I built this kind of system for a real media platform to power intelligent search and recommendations over content catalogs. The architecture here follows the same pattern, adapted as a self-contained tutorial. It’s not trivial, but follow each step and you’ll have a real agent, not a demo toy.
Configuring Poetry
Because manually managing dependencies is suffering we no longer accept.
poetry initpyproject.toml
[tool.poetry]
name = "ai-react-agent-azure"
version = "0.1.0"
[tool.poetry.dependencies]
python = "^3.10"
langchain = "^0.3.14"
langchain-openai = "^0.3.0"
langgraph = "^0.2.62"
streamlit = "^1.41.1"
elasticsearch = "^8.17.1"
neo4j = "^5.28.1"
python-dotenv = "^1.0.1"poetry shell
poetry installState (state.py)
LangGraph is state-machine based. This file defines the shared state object that flows between every node in the agent graph.
from typing import Annotated, TypedDict, Union
from langchain_core.agents import AgentAction, AgentFinish
import operator
class AgentState(TypedDict):
input: str
agent_outcome: Union[AgentAction, AgentFinish, None]
intermediate_steps: Annotated[list[tuple[AgentAction, str]], operator.add]Tools (tools.py)
The toolbox. Because a ReAct agent without tools is just a very opinionated chatbot. The agent has four tools: vector search via Elasticsearch, social graph recommendations via Neo4j, promotion queries, and a general chat fallback.
ReAct agent (react.py)
This is where the magic happens, or where you spend 3 hours debugging why the agent keeps calling the wrong tool.
from langchain import hub
from langchain.agents import create_react_agent
from langchain_openai import ChatOpenAI
react_prompt = hub.pull("hwchase17/react")
llm = ChatOpenAI(model="gpt-3.5-turbo-1106")
react_agent_runnable = create_react_agent(llm, tools, react_prompt)Nodes (nodes.py)
from langgraph.prebuilt.tool_executor import ToolExecutor
def run_agent_reasoning_engine(state: AgentState):
agent_outcome = react_agent_runnable.invoke(state)
return {"agent_outcome": agent_outcome}
tool_executor = ToolExecutor(tools)
def execute_tools(state: AgentState):
agent_action = state["agent_outcome"]
output = tool_executor.invoke(agent_action)
return {"intermediate_steps": [(agent_action, str(output))]}Graph (run.py)
from langgraph.graph import END, StateGraph
def should_continue(state: AgentState) -> str:
if isinstance(state["agent_outcome"], AgentFinish):
return END
return "act"
flow = StateGraph(AgentState)
flow.add_node("agent_reason", run_agent_reasoning_engine)
flow.add_node("act", execute_tools)
flow.set_entry_point("agent_reason")
flow.add_conditional_edges("agent_reason", should_continue)
flow.add_edge("act", "agent_reason")
app = flow.compile()Configuring Elasticsearch locally
sudo apt-get install elasticsearch -y
sudo systemctl enable elasticsearch
sudo systemctl start elasticsearch
sudo /usr/share/elasticsearch/bin/elasticsearch-reset-password -u elastic -iConfiguring Neo4j locally
sudo apt install neo4j -y
sudo neo4j-admin set-initial-password yourpassword
sudo systemctl enable neo4j
sudo systemctl start neo4j
# Access: http://localhost:7474/browser/What you’ve built
A complete, production-pattern AI agent: a LangGraph ReAct loop that orchestrates Azure OpenAI reasoning, Elasticsearch vector search, and Neo4j graph-based recommendations, wrapped in a Streamlit interface. The architecture handles tool selection, verification, and graceful fallback. More importantly, it runs the same pattern whether your databases are local or cloud services.
Next steps
- Add LangSmith tracing to observe every reasoning step and tool call. Invaluable when the agent starts doing something unexpected.
- Extend the tools layer with a database specific to your domain and watch the agent specialize without changing the graph structure.
- Deploy the Streamlit app as a containerized service on Azure Container Apps with managed identity, so API keys never sit in environment files on a server.
Questions or feedback? Find me on LinkedIn or GitHub.